In this blog, I will try to explain what exactly is gradient descent and it’s importance in optimizing machine learning models. Gradient descent is an algorithm (just like million other algorithms that exists in computer science) that is designed to minimize a cost function.
What is a cost function?
- Well, it is essentially the error between predicted and actual outputs. Which means if we want to increase our model’s accuracy, we need to somehow reduce this cost function and for that we’ve got gradient descent.
What is a Gradient?
- A gradient is essentially the derivative of a function, which tells us how the output is affected with little variations in input. This gradient, helps us in adjusting model parameters (like weights and biases) to reduce the cost function.
Why Gradient Descent?
- It helps us in minimizing the error in predictions, bringing the model closer to the actual data. It iteratively keep adjusting the model’s parameters until minimum cost function state is achieved.
- This iterative process ensures the model learns and improves its performance.
What are Weights and Biases?
Weights: Weights (W) are parameters that define influence of an input on the model’s output. Biases: Biases (b) is an additional parameter that shifts the model’s prediction.
For Example, If we consider a model that is trained to determine house prices based on the area (in Sq. m), then in this case area’s impact on the price of the house is weight and other factors such as location, or the number of bedrooms are biases that can shift the prediction.
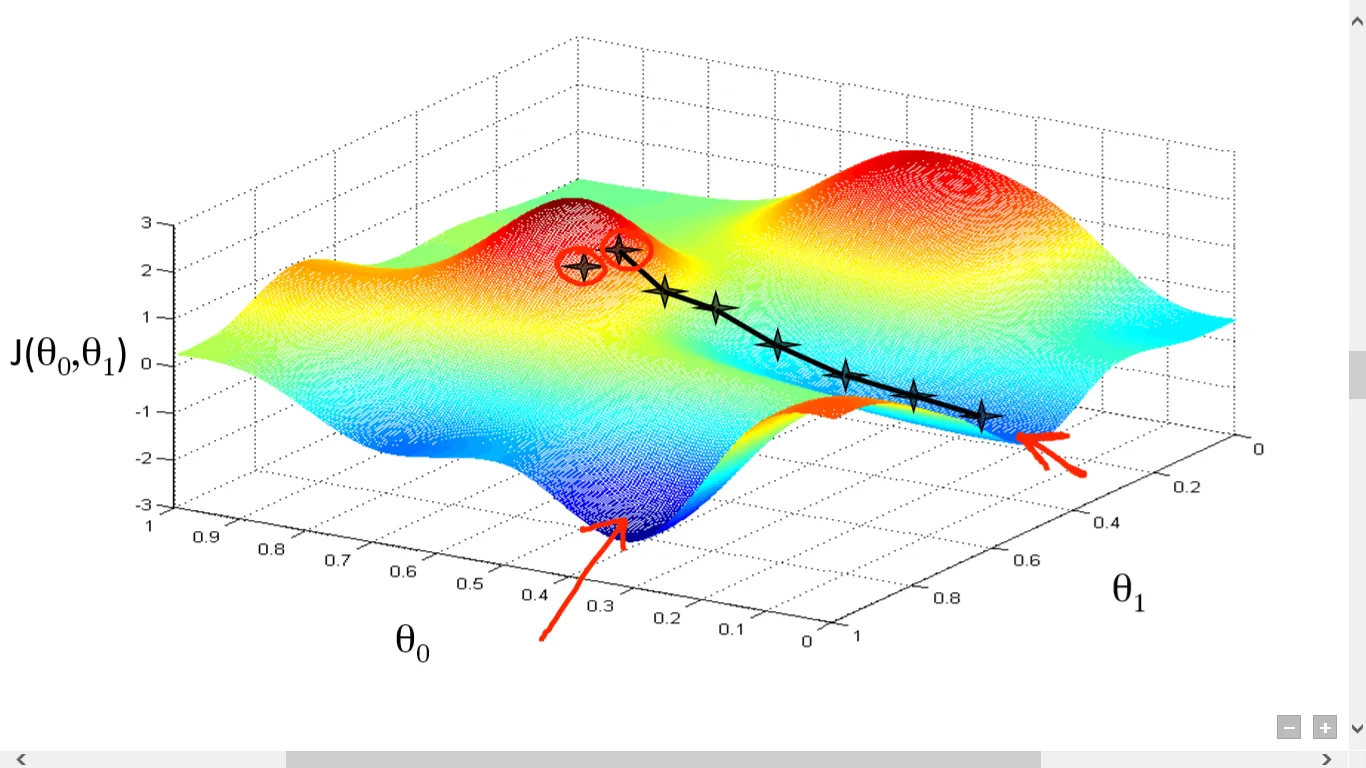
How does Gradient Descent Work?
Firstly, we take a starting point (it can be any point as it’s just an arbitary point for us to evaluate the performance). Then the derivative (or slope) is calculated at this point, after which we can use a tangent line to observe the steepness of the slope. Finding out the slope is an important step as it will inform what updates need to be made to the parameters- i.e. the weights and bias. The starting point of the slope will be steeper, but as new parameters are generated, the steepness will gradually reduce and will slowly near zero as we reach the lowest point on the curve. This lowest point on the curve is known as the point of convergence.
Like in linear regression, we try to find the bet fit line, the goal of gradient is to minimize the error between the predicted y and the actual y. In order to achieve this goal, it requires two data points- a direction and a learning rate. These factors determine the partial derivative calculations of future iterations, allowing it to gradually arrive at the local or global minimum (i.e. point of convergence).
Steps:
1. Starting Point: Begin with initial parameter values, often set arbitrarily. 2. Calculate the Slope: Determine the gradient at this point to assess the steepness and direction of the slope. 3. Update Parameters: Use the slope to adjust the parameters, iteratively reducing the steepness until the curve flattens at the minimum. 4. Convergence: Continue until the gradient approaches zero, signifying that the minimum has been reached.
Key Components
-
Learning Rate (α) Determines the size of step we take after each calculation or the variation in input.
- High learning rate takes larger steps which speeds up the process but also increases the risk of overshooting the minimum.
- Low learning rate ensures precise steps but increases computation time as the number of iterations increases.
-
Cost Function The cost function quantifies the error between the predicted output and the actual output.
- It guides the model by providing feedback, enabling parameter updates to minimize the error.
- A loss function refers to the error for a single training example, while the cost function averages this error across the entire dataset.